Aggregate (DDD)
An Aggregate is an abstraction for an object that is important and of value to the business of its domain. It is often referred to as a "cluster" of objects, because it is modelled as a whole/parts-relationship holding Associations between Entities and Value Objects.
Aggregates are not to be understood as data-structures: They have particularly responsibility for carrying out and applying logic and behavior characteristic to the Bounded Context they belong to.
An Aggregate is uniquely identifiable given high-level code semantics, e.g. through (one of) its attributes.
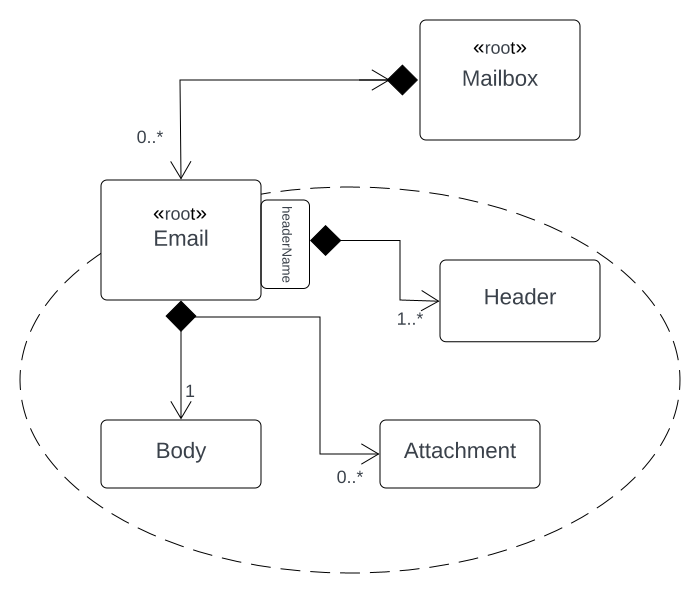
Figure 1 depicts the Aggregate-model of an Email. This model suggests a simpification of an Email-message in a way that clients do not have to be aware of the intricate structure [RFC2822] of an Email, but rather can add and remove attachments, edit its message body and update header fields given the interface provided by the Aggregate Root, Email.
Another Aggregate in form of the Mailbox (i.e. the folder that owns the Email) can provide access to its Emails.
Aggregate Root
The root of the Aggregate guards the objects of the Aggregate and is the only object that grants access to its elements. It is also responsible for making sure that any Aggregate-defining invariants are not violated when business logic is applied, or during creation or reconstitution from a persistent state.
Identities of such embedded objects are often only of importance within and to the Aggregate. Thus, an Aggegrate also designates a consistency boundary so that parts of the Aggregate may not be accessed from outside to prevent violating the consistency. Control must only be given by the Aggregate Root. In such cases, it is preferable to satisfy interested clients with transient references, often in the form of Value Objects so any state of the Aggregate does not get accidentally changed, e.g. through Aliasing Bugs.
Invariants
Invariants for the Aggregate are rules that apply to the whole and are validated against its parts. The state of the Aggregate is only valid if no invariant is violated. Invariants can be simple checks which make sure that the format of field-values is valid, or more complex ones where specifications encapsulate business rules.
Transactional Consistency
When the state of an Aggregate is persisted, the whole Aggregate must be committed, including any changes made to the state of its parts. The implementation has to make sure that affected Aggregates are updated using appropriate methodologies, such as Eventual Consistency. The design of the **Aggregate should make sure that the boundaries of such conceptual related abstractions are meaningful to the model as well as the system, where non-functional requirements such as scalability and performance also apply.
It is suggested to design Aggregates small: They should not become object graphs of (large) relational models, but it should also be taken care of meaningful transactional boundaries: Committing changes of an Aggregate should not require the update a large number of fine-granular conceptual related Aggregates. The existence of such aggregates should be questioned and reconciled with the model that triggered the state-change in the first place. On the other hand, such a transaction should not lock the data-model down so that concurrent operations on related Aggregates are not put to an hold.
Questions that can help with designing Aggregates are, amongst others:
- How many transactions are required to successfully commit changes to the Aggregate?
- What are the transactional boundaries?
- Are there any invariants redundant to invariants of other conceptual related Aggregates?
A detailed discussion on designing Aggregates is given with [📖IDDD, pp. 347-388].
"(Therefore,) Aggregates are (chiefly) about consistency boundaries and not driven by a desire to design object graphs." [📖IDDD, p. 355]
references