[DE] Shellsort Laufzeitanalyse

Donald Shell stellt 1959 in [📖She59] einen Sortieralgorithmus vor, der später nach ihm benannt wird: Shellsort.
Die in dem Algorithmus verwendete Sortiermethode ist auch bekannt als
Sortieren mit abnehmenden Inkrementen [���📖OW17b, 88], das Verfahren ist eine Variation von Insertion Sort:
[Shellsort] uses insertion sort on periodic subarrays of the input to produce a faster sorting algorithm. [📖CL22, 48]
In der vorliegenden Implementierung (siehe Listing 1) werden Inkremente1 2 der Form verwendet, um -sortierte Folgen zu erzeugen. Im letzten Schritt sortiert der Algorithmus dann in die Schlüssel mit Abstand=.
Die Effizienz des Sortierverfahrens ist stark abhängig von : So zeigt Knuth, dass gilt, wenn für gilt: mit (vgl. [📖Knu97c, 91]3. In unserem Fall können wir von ausgehen.
Anzahl der Aufrufe für Feldvergleiche
Gesucht ist die Anzahl der zwischen zwei Feldelementen gemachte Vergleiche für große randomisierte Felder. Wir vermuten hierfür einen Wert zwischen und ,
Um die Aufrufe der Feldvergleiche zu zählen, kann wie in Listing 1 eine Zählvariable eingesetzt wird, die jeden Aufruf über ein increment protokolliert.
while (distanz > 0) {
c1++;
for (i = distanz; i < feld.length; i++) {
j = i - distanz;
c2++;
while (j >= 0) {
c3++;
if (feld[j] > feld[j + distanz]) {
c4++;
swap(feld, j, j+distanz);
j = j - distanz;
} else {
j =-1;
}
}
}
distanz = distanz / 2;
}
Zur Bestimmung von können randomisierte Felder erzeugt werden, wie es der Test-Code in Listing 2 demonstriert. Dann wird überprüft, in welchen Bereichen sich bewegt. Da jeder auf Vergleichsoperationen basierende Sortieralgorithmus zu der Laufzeitklasse gehört, kann im Mittel angenommen werden:
Jedes allgemeine Sortierverfahren benötigt zum Sortieren von N verschiedenen Schlüsseln sowohl im schlechtesten Fall als auch im Mittel wenigstens Schlüsselvergleiche.
[📖OW17b, 154]
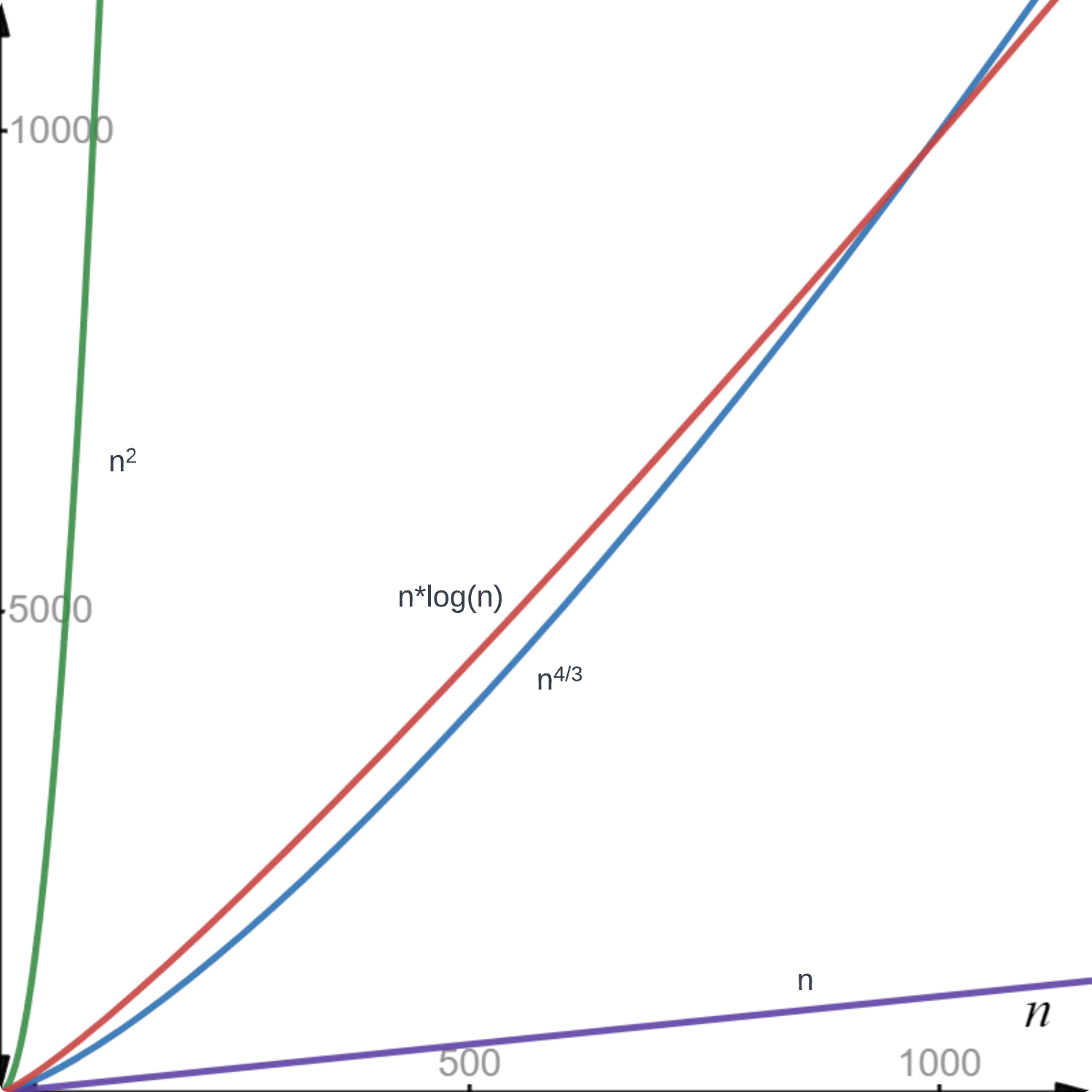
Allerdings wird ab schneller wachsen als (siehe Abbildung 1), was in der Auswertung berücksichtigt werden muss. Sonst könnte man fälschlicherweise folgern, das in dem geg. Fall die Laufzeit im Durchschnitt beträgt.
int epochs = 2000;
while(epochs-- >= 0) {
int[] tests = new int[]{10, 100, 1000, 100_000, 1_000_000};
java.util.Random r = new java.util.Random();
for (int i = 0; i < tests.length; i++) {
int l = tests[i];
int[] arr = new int[l];
for (int j = l; j > 0; j--) {
arr[l - j] = r.nextInt(l + 1);
}
ShellSort.sort(Arrays.copyOfRange(arr, 0, arr.length));
}
}
Mit einem Wert von für die Epochen und einer Feldgröße von liefert der Test in Listing 2 folgende Ausgabe:
Wegen interessieren wir uns für die Intervalle:
Die Ausführung des Tests zeigt, dass die Aufrufanzahl von bei großen unterhalb oder zwischen und liegt:
It appears that the time required to sort elements is proportional to .4 [📖She59, 31]
Laufzeitanalyse
Für die nachfolgenden Betrachtungen sei eine Eingabegröße gegeben. Die Inkremente entsprechen der über die Implementierung vorgegebenen Folge mit
Für die Analyse ist die Shellsort-Implementierung in Listing 3 gegeben.
public static int[] sort(int[] arr) {
int n = arr.length;
int delta = n/2;
int min;
int j;
while (delta > 0) { // c1
for (int i = delta; i < arr.length; i++) {
// c2
min = arr[i];
j = i;
while (j - delta >= 0 && min < arr[j - delta]) {
// c3;
arr[j] = arr[j - delta];
j -= delta;
}
arr[j] = min;
}
delta = delta / 2;
}
return arr;
}
Im Folgenden betrachten wir die Anzahl für die im Code durch Kommentare markierten Stellen in Zeile 8, in Zeile 12 und in Zeile 19.
Für eine erste worst-case-Analyse ist ein Feld der Länge gegeben, in absteigender Reihenfolge sortiert (s. Abbildung 2):

Ganz offensichtlich gilt für c3, dass es -mal aufgerufen wird5. c2 befindet sich im Block der durch die in Zeile 11 definierten Zählschleife.
Der Startwert für i ist in jedem Durchgang des Blocks der aktuelle
Wert von delta 6, und läuft jeweils bis .
In einem kompletten Durchlauf der Schleife entspricht die Anzahl der Aufrufe von also
Hinweis:
Für das Beispiel betrachten wir der Einfachheit halber Feldlängen der
Form .
Für den allgemeinen Fall gilt für die Anzahl der Aufrufe von :
Für die Gesamtzahl der Aufrufe von ergibt sich somit unter Berücksichtigung von
was nach Auflösen
entspricht, und für unser Beispiel
ist.
Die Aufrufzahlen für für verschiedene . Schlüsselvergleiche finden erst später statt. Mit wächst schneller als und mit schneller als .
| n | c2 | ||||
|---|---|---|---|---|---|
| 8 | 17 | 9 | 14 | 24 | 64 |
| 16 | 49 | 21 | 36 | 64 | 256 |
| 32 | 129 | 45 | 90 | 160 | 1024 |
| 64 | 321 | 97 | 222 | 384 | 4096 |
| 128 | 769 | 207 | 548 | 896 | 16.384 |
| 256 | 1793 | 445 | 1351 | 2048 | 65.536 |
| 1024 | 9217 | 2048 | 8192 | 10240 | 1.048.576 |
| 2156 | 21.565 | 4.645,29 | 21.564,69 | 23.875,84 | 4.648.336 |
| 2157 | 21.576 | 4.647,66 | 21.577,70 | 23.888,36 | 4.652.649 |
| 2158 | 21.586 | 4.650,03 | 21.590,70 | 23.900,88 | 4.656.964 |
| ... | ... | ... | ... | ... | ... |
| 10.000 | 120.005 | 25.118 | 158.489 | 132.877 | 1.0E8 |
| 100.000 | 1.500.006 | 316.227 | 3.162.277 | 1.660.964 | 1.0E10 |
| 200.000 | 3.200.006 | 677.849 | 7.786.440 | 3.521.928 | 4.0E10 |
| 500.000 | 8.500.007 | 1.857.235 | 2.56..E7 | 9.465.784 | 2.5E11 |
| 1.000.000 | 18.000.007 | 3.981.071 | 6.30..E7 | 1.99..E7 | 1.0E12 |
In der while-Schleife in Zeile 17 findet die eigentliche
Arbeit des Algorithmus statt: Es wird überprüft, ob -entfernte
Elemente in aufsteigender Reihenfolge sortiert angeordnet sind.
Ist das nicht der Fall, werden die Elemente an den Stellen und
ausgetauscht, bis die -Folge sortiert ist.
Für den ersten Durchgang des Algorithmus an dieser Stelle mit
ergibt sich somit die in Abbildung 3 dargestellte Reihenfolge der Schlüssel:

Die weiteren Durchgänge des Algorithmus sortieren das Feld entsprechend der Größe : Es sind danach jeweils Schlüssel mit den Abständen (Abbildung 4 und (Abbildung 5) sortiert; im letzten Schritt dann vollständig (Abbildung 6):



Für die Berechnung der Anzahl der Aufrufe von stellt man fest, das in diesem Fall in jedem Schritt immer 2 Elemente, die eine Distanz von aufweisen, falsch sortiert sind.
Der Algorithmus tauscht daraufhin in jedem Durchgang alle
Schlüssel untereinander aus, die er über min < arr[j-delta] miteinander vergleicht, was
folglich die maximale Anzahl von Schlüsselvertauschungen in dieser
vergleichsbasierten Implementierung für ein Feld der Größe ergibt,
nämlich . Insgesamt finden dadurch für
Aufrufe statt.
Mit der Anzahl der berechneten Aufrufe ergibt sich somit für die Laufzeit für diesen Fall
und zusammengefasst
was nach Einsetzen zu
Aufrufen für unser Beispiel führt.
Nachweis der Komplexitätsklasse
Um zu ermitteln, werden nun alle Konstanten der Funktion
eliminiert, und der "dominante" Summand in Abhängigkeit von betrachtet, der in diesem Fall ist.
Wir vermuten ein -Wachstum7 (vgl. [📖OW17a, 5]), und wollen
nun zeigen, dass in liegt.
Hierfür müssen wir ein geeignetes und ein finden, so dass gilt:
(vgl. [📖GD18a, 11]).
Zu zeigen ist
Wir wählen für und , denn es gilt sicher
.
Ausserdem gilt stets , woraus folgt, und damit auch .
Insgesamt gilt also
womit gezeigt ist. ◻
Worst-Case-Analyse
Unter der Annahme, dass ein in umgekehrter Reihenfolge sortiertes Feld
zu einer Laufzeit von bei dem Shellsort-Algorithmus führt,
konnten wir mit dem in dem vorherigen Abschnitt gewählten Parametern nur
eine Laufzeit von nachweisen.
Tatsächlich stellt der Anwendungsfall nicht den worst-case für den
Algorithmus dar, da ja gerade diese Form von Sortierreihenfolge dem
Algorithmus die Vorsortierung der -Folgen ermöglicht:
The idea underlying Shellsort is that moving elements of A long distances at each swap in the early stages, then shorter distances later, may reduce this bound. [📖Pra72, 3]
Es gilt also, die Vorsortierung auszuhebeln.
Für Insertion-Sort ist die Laufzeit im worst-case
(vgl. [📖OW17b, 87]). Da Shellsort mindestens im letzten Schritt diese
Sortiermethode auf Distanzfolgen der Länge anwendet, muss der
Algorithmus eine Folge als Eingabe erhalten, die durch die ersten
-Durchgänge (mit )
keine Änderungen erfährt, um dann
im allerletzten Schritt auf einen Schlag sortiert wird, was
maximal Inversionen8 bedeutet, und damit ebenso viele Vertauschungen (zuzüglich der benötigten
Verschiebe-Operationen).
Hierzu kann wie im vorherigen Beispiel für ein Feld mit folgender
Schlüsselanordnung verwendet werden: Felder mit geradem Index enthalten
kleinere Schlüssel als Felder mit ungeradem Index. Hier gilt für alle
Elemente aus dem Feld :
Abbildung 7 veranschaulicht die Anordnung.

Markiert sind die direkt benachbarten Felder, die eine Inversion
aufweisen, die im letzten Schritt des Algorithmus eine bzw. mehrere
Verschiebungen bedingen.
In den vorherigen Schritten - also bei den Durchgängen mit Distanzfolgen
- findet der Algorithmus jeweils Schlüssel in korrekter
Sortierreihenfolge vor.
Mit werden die Felder mit den Feldern verglichen - hier gilt in jedem Fall, dass die Schlüssel sind.
Auch im darauffolgenden Durchgang () finden keine Verschiebungen statt, da keine Inversion gefunden wird. Erst im letzten Schritt, in dem direkt benachbarte Elemente miteinander verglichen werden, werden die Inversionen ermittelt und die Verschiebung der Elemente findet statt (s. Abbildung 8.
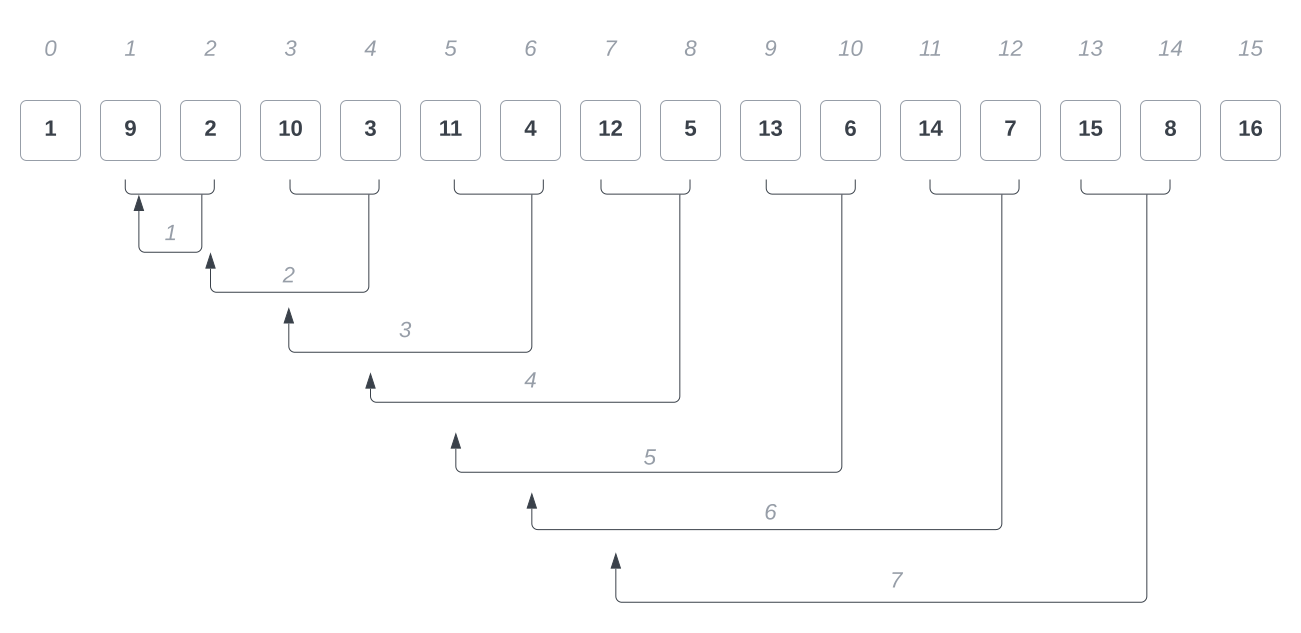
In diesem Fall wird insgesamt mal aufgerufen.
Da jeweils zwei Schlüssel bereits korrekt sortiert sind ( und ) existieren noch Inversionen. Jede Inversion erzwingt eine Verschiebung des größten Elements um Positionen nach links.
Für die Berechnung der Laufzeitkomplexität ergibt sich somit der Term
und unter Berücksichtigung der Terme für , , die Funktion
was zu einer Laufzeitabschätzung von führt.
Footnotes
-
mit Länge des zu sortierenden Feldes. Im folgenden für . ↩
-
vgl. [📖Knu97c, 84] ↩
-
Knuth bezieht sich hier auf die Arbeit von Papernov und Stasevich ([📖PS65]). Weitere Verweise auf Laufzeiten in Abhängigkeit von und fasst übersichtlich der Wikipedia-Artikel zusammen: https://en.wikipedia.org/wiki/Shellsort (abgerufen 23.01.2024). ↩
-
Shell führt in seinem Paper keinen Beweis auf. Er stützt seine Behauptung auf Messungen, die er selber in Tests durchgeführt hat: "[...] an analytical determination of the expected speed has eluded the writer. However, experimental use has established its speed characteristics." (ebenda) ↩
-
hier wie im folgenden ohne Betrachtung der Schleifenbedingung, die an dieser Stelle insgesamt -mal aufgerufen wird ↩
-
für das gegebene Beispiel ↩
-
mit bzw nehmen wir für die -Notation wieder die in der Fachliteratur gebräuchlichere Schreibweise auf. Sowohl Güting und Dieker als auch Ottmann und Widmayer weisen in [📖GD18a, 15] bzw. [📖OW17a, 5] darauf hin, dass die Angabe der Basis keine Rolle spielt, da sich Logarithmen mit verschiedenen Basen ohnehin nur durch einen konstanten Faktor unterscheiden (es gilt ). ↩
-
in diesem Zusammenhang bedeutet Inversion: Fehlstellung (vgl. [📖OW17b, 87]) ↩
References
- [She59]: Shell, D. L.: A High-Speed Sorting Procedure (1959), 10.1145/368370.368387 [BibTeX]
- [OW17b]: Ottmann, Thomas and Widmayer, Peter: Sortieren (2017), Springer Berlin Heidelberg, 10.1007/978-3-662-55650-4_2 [BibTeX]
- [CL22]: Cormen, Thomas H. and Leiserson, Charles E. and Rivest, Ronald L. and Stein, Clifford: Introduction to Algorithms (2022), MIT Press [BibTeX]
- [Knu97c]: Knuth, Donald E.: The Art of Computer Programming, Volume 3 (2nd Ed.): Sorting and Searching (1997), Addison Wesley Longman Publishing Co., Inc. [BibTeX]
- [OW17a]: Ottmann, Thomas and Widmayer, Peter: Grundlagen (2017), Springer Berlin Heidelberg, 10.1007/978-3-662-55650-4_1 [BibTeX]
- [GD18a]: Dieker, Ralf Hartmut and Dieker, Stefan: Einführung (2018), Springer Fachmedien Wiesbaden, 10.1007/978-3-658-04676-7_1 [BibTeX]
- [Pra72]: Pratt, Vaughan R.: Shellsort and Sorting Networks (1972) [BibTeX]
- [PS65]: Papernov, A. A. and Stasevich, G. V.: A Method of Information Sorting in Computer Memories (1965) [BibTeX]