From Camera to Clip Space - Derivation of the Projection Matrices
We derive the orthographic and perspective projection matrices used in 3D computer graphics, with special emphasis on OpenGL conventions. Starting from camera-space geometry, we construct the projection that maps to clip space, explain clipping via the clip-space inequalities, and show how the subsequent perspective divide produces normalized device coordinates in the canonical view volume. Along the way, we show that affine transformations preserve parallelism. We clarify the roles of the - and -components: Depth in NDC arises from , with carrying the perspective scaling. The result is a compact, implementation-oriented account of Field-of-View, aspect ratio and near-/far-plane parameters.
Introduction
This article describes one of the final steps in the rendering pipeline: Projection and perspective transformations.
While in perspective projection all projection lines converge at a single point - producing the familiar sense of depth - in orthographic projection these lines run parallel to each other. With this projection type, parallel lines therefore remain parallel even after mapping onto the so-called unit cube.
We begin with the orthographic projection and derive a projection matrix that maps an arbitrary view volume onto the so-called unit cube. Along the way, we use figures to show how an orthographic projection affects objects we usually perceive in a perspective manner.
We then derive the perspective projection and show how choosing a near and a far viewing plane, as well as a height and a width encoded in the aspect ratio, creates a so-called view frustum that contains the objects visible to the observer, while any geometry outside of it is clipped and discarded from the rendering process.
Projection Planes
In the final steps of the rendering pipeline, the perspective divide converts clip-space coordinates to normalized device coordinates1; the viewport transform maps them to screen space, and rasterization produces the 2D image.
Before this happens, a view matrix is constructed that transforms world coordinates into camera coordinates2, defined by a vantage point , the observed point and a vector representing the camera’s up direction at camera at looking at .
Transforming world coordinates into camera coordinates isn’t particularly helpful on its own. In a scene graph with hundreds of nodes, we still have to decide which ones should actually appear on screen. Even with a known viewer position and look direction, the camera is still just an idealized point; without a defined viewing volume, no geometry will be captured, and the resulting image will be empty. Conversely, knowing only the viewport's height and width defines the aspect ratio, but it tells us nothing about the field of view, depth range, or clipping planes.
In general, the camera implicit in computing camera coordinates is a pinhole camera - an idealized model with an infinitesimally small aperture that admits rays and produces an image. We push the abstraction a step further: In computer graphics we don’t capture photons, we trace geometric lines from the scene’s vertices through the pinhole onto a projection plane. Take the camera obscura3 as a figurative example, where we place a screen behind the pinhole and the projected points meet on that plane, yielding a mirrored, upside-down image (see Figure 1).
In the following, we will define the viewing volume for both orthographic and perspective projections. We will determine the size of the projection plane and its distance from the camera and examine how these parameters determine the view frustum, which specifies which objects in the scene are ultimately rendered.
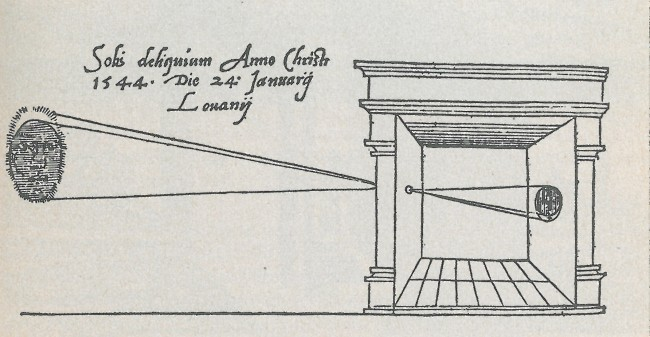
Excursus: View Space, Clip Space, the Canonical View Volume and NDCs
In the following, we will give a brief introduction to clipping, which is a process that discards geometry outside of a view volume. In short, primitives removed during clipping will not be part of the Canonical View Volume which contains all necessary geometry passed on to the final rasterization and on-screen display stages of the rendering pipeline.
Clipping is done by OpenGL with the help of the homogeneous coordinate component . The following introduces the process with the help of orthographic projection, but it can be applied analogously with perspective projection, as we will see later.
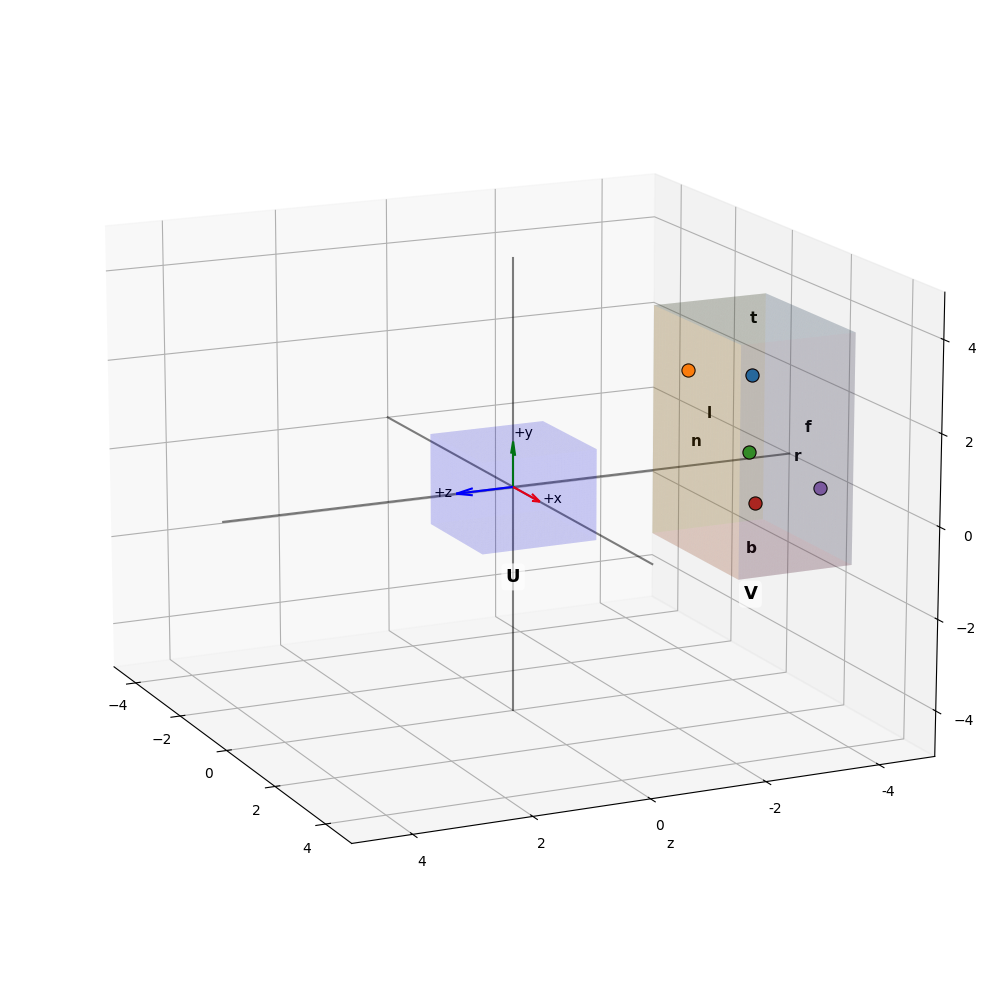
In camera space, the six planes of a view volume specify the clipping planes (see Figure 2). Roughly speaking, all vertices within this view volume are considered to be preserved for rendering.
After multiplying a vertex with the projection matrix, the vertex shader's homogeneous coordinate
gl_Position =
is in clip space4.
OpenGL then performs clipping of the primitives against the inequalities [📖KSS17, Figure 5.2, 201]5
Primitives outside clip space are discarded, while the visible portion of intersecting primitives is rasterized [📖SWH15, 2 96ff.].
Once clipping has finished, the clip coordinates are mapped to Normalized Device Coordinates by the perspective divide
This yields the coordinates within the canonical view volume. Since every surviving clip coordinate satisfies the clipping inequalities (e.g., ), every component of the resulting NDC coordinate is guaranteed to lie in the interval [-1, 1]6.
The Canonical Unit Cube, or canonical view volume [📖RTR, 94], defined by the interval 7 on all three axes, is the space for Normalized Device Coordinates in OpenGL.
In the rendering pipeline, NDCs are produced by applying the perspective divide to the clip space coordinates that result from the projection transform. With orthographic projection, it follows that . The coordinates resulting from this normalization step are then mapped to the user's specific device resolution (see [📖LGK23, Fig. 5.36, 181]).
When using orthographic projection, the clip space falls together with the NDCs, as the perspective division by the fourth homogeneous -coordinate is applied, but does not change the -coordinates (see [📖SWH15, 72]).
Let be a point in view space. This is in homogeneous coordinates
After transforming into clip space, the point is mapped to
Let . Then, the following holds:
Obviously, since
the inequality
holds.
Applying the same premise and same logic to shows that is in .
Therefor, any point that is not clipped before the perspective divide must satisfy the inequalities
which yields a point in NDC in the Canonical View Volume in OpenGL8 that satisfies
Orthographic Projection
When we apply orthographic projection, points are projected onto an arbitrary plane.
Visually, it appears as if we are reducing the vector space by one dimension. A key property is that parallel lines remain parallel, regardless of the camera's orientation, and the perspective component is eliminated.
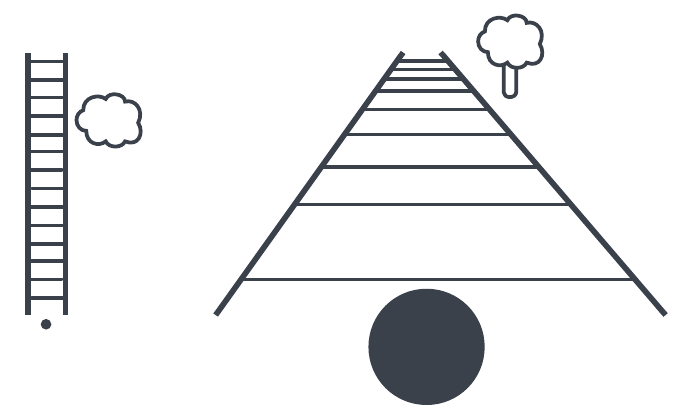
To explain this intuitive sense of depth and the apparent contradiction with parallel lines, the example of railroad tracks is often used: While we can assume that railroad tracks are parallel not only at the observer's standpoint but also a kilometer in the distance, the effect of depth makes it seem as though the tracks converge at a single point, known as the vanishing point (see Figure Figure 6).
For eliminating the z-component of any given , we can use the following matrix:
From this matrix form it immediately follows that any homogenous vector multiplied with this matrix yields a vector with its z-component set to :
To project onto an arbitrary z-plane, we use the z-component of the 4 column in the matrix and construct a transformation matrix
This gives us
We can easily derive that any vector computed by this must be perpendicular to the plane given by the vectors and , since their crossproduct yields
which is a vector with .
It is easily shown that this vector is parallel to since
The effect of projecting the points of a (wireframed) cube is shown in the animations Figure 3, Figure 5, Figure 4.
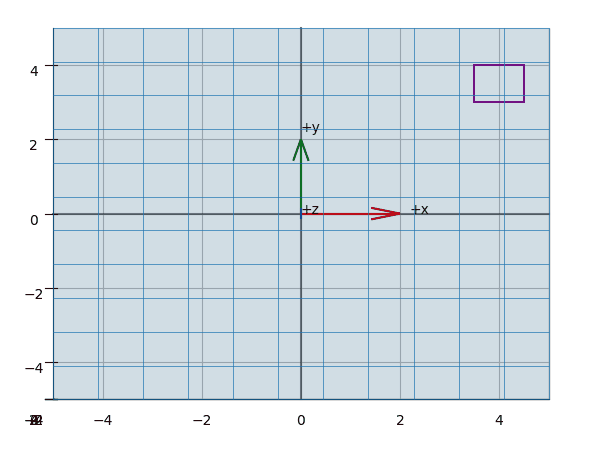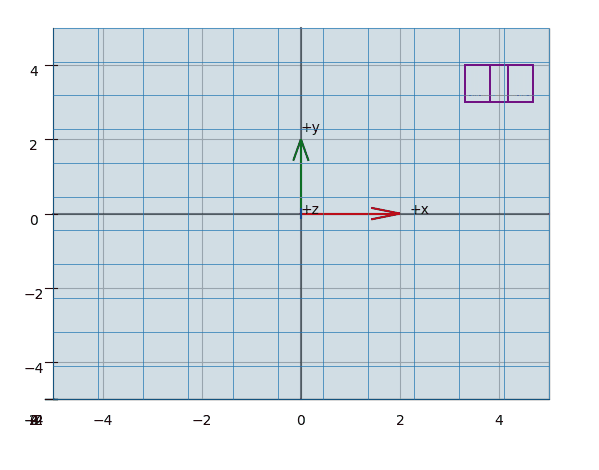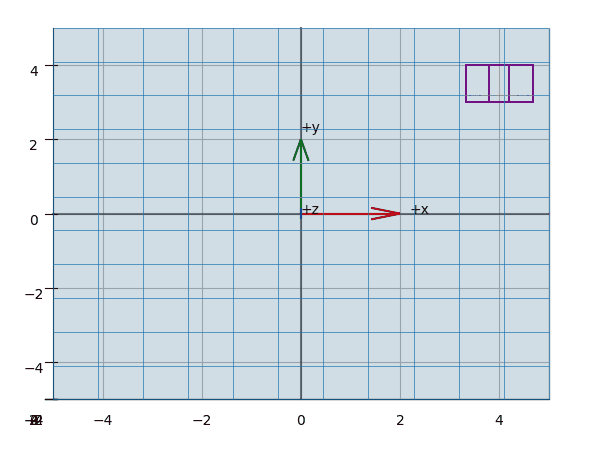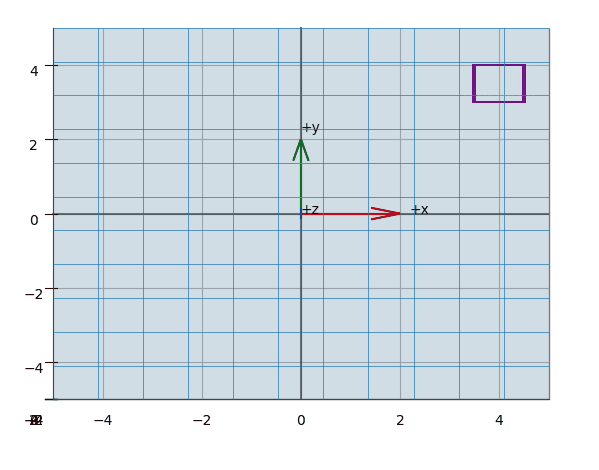
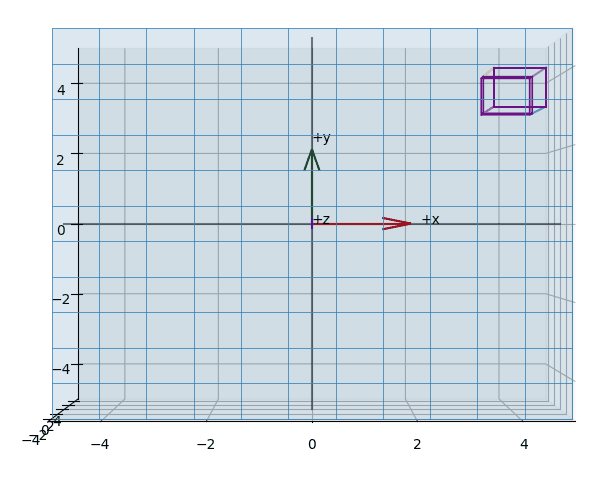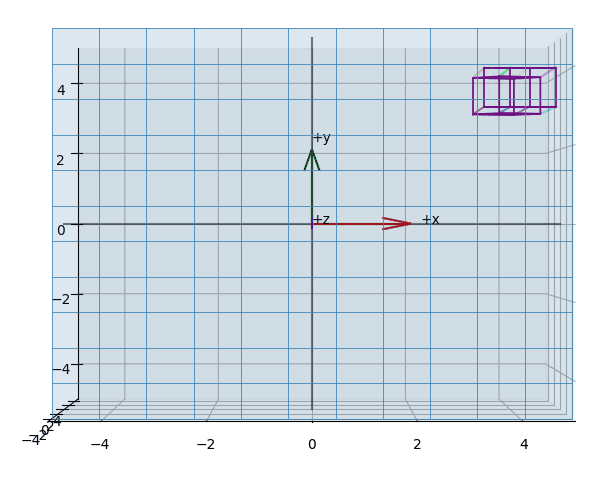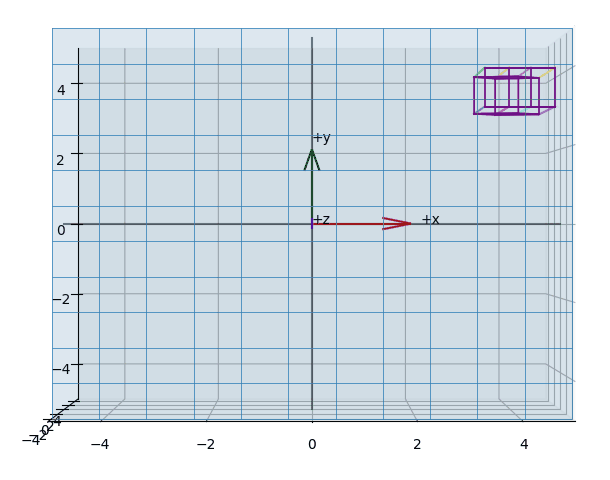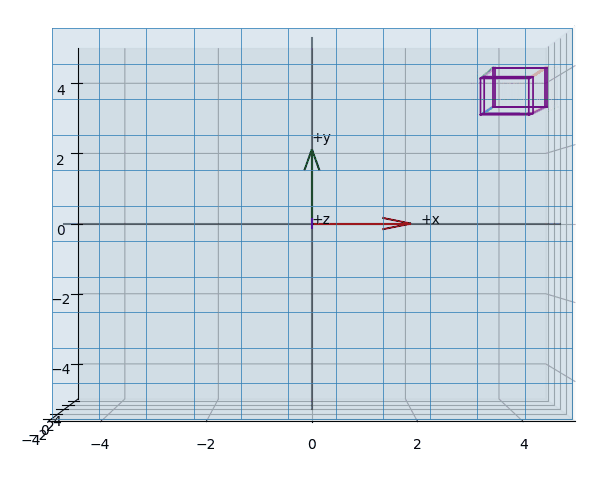
Plot-Code (Python)
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # noqa: F401
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
import math
from matplotlib.animation import FuncAnimation
# Convention: x -> right, y -> up, z -> toward viewer. (rhs)
def rotate(theta, n, v, pivot):
v = v-pivot
theta = theta * math.pi/180
vn = v / np.linalg.norm(v)
nn = n / np.linalg.norm(n)
vpar = np.dot(nn, v) * nn
vperp = v - vpar
return vpar + (np.cos(theta) * (vperp)) + (np.sin(theta) * np.cross(nn, v)) + pivot
def to_matplotlib(xu, yu, zu):
return xu, zu, yu
xr = (-5, 5)
yr = (-5, 5)
zr = (5, -5)
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111, projection='3d')
# set to ortho for orthographic projection of the plot
# ax.set_proj_type('ortho')
def init():
ax.set_xlim(*xr)
ax.set_ylim(-zr[0], -zr[1])
ax.set_zlim(*yr)
z_plane = -4.0
x = np.linspace(xr[0], xr[1], 40)
y = np.linspace(yr[0], yr[1], 40)
Xg, Yg = np.meshgrid(x, y)
Xm, Ym, Zm = to_matplotlib(Xg, Yg, z_plane)
ax.plot_surface(Xm, Ym, Zm, alpha=0.15, linewidth=0, antialiased=True)
# Wireframe
xw = np.linspace(xr[0], xr[1], 12)
yw = np.linspace(yr[0], yr[1], 12)
Xw, Yw = np.meshgrid(xw, yw)
Xm_w, Ym_w, Zm_w = to_matplotlib(Xw, Yw, z_plane)
ax.plot_wireframe(Xm_w, Ym_w, Zm_w, rstride=1, cstride=1, linewidth=0.5)
# Coordinate axes in USER coordinates
Xline = np.linspace(xr[0], xr[1], 2)
Xm_ax, Ym_ax, Zm_ax = to_matplotlib(Xline, 0*Xline, 0*Xline)
ax.plot(Xm_ax, Ym_ax, Zm_ax, color="black", alpha=0.5)
Yline = np.linspace(yr[0], yr[1], 2)
Xm_ay, Ym_ay, Zm_ay = to_matplotlib(0*Yline, Yline, 0*Yline)
ax.plot(Xm_ay, Ym_ay, Zm_ay, color="black", alpha=0.5)
Zline = np.linspace(zr[0], zr[1], 2)
Xm_az, Ym_az, Zm_az = to_matplotlib(0*Zline, 0*Zline, Zline)
ax.plot(Xm_az, Ym_az, Zm_az, color="black", alpha=0.5)
arrow_len = 2.0
# +x
dx, dy, dz = to_matplotlib(1, 0, 0)
ax.quiver(0, 0, 0, dx, dy, dz, color="red", length=arrow_len, normalize=True)
# +y
dx, dy, dz = to_matplotlib(0, 1, 0)
ax.quiver(0, 0, 0, dx, dy, dz, color="green", length=arrow_len, normalize=True)
# +z
dx, dy, dz = to_matplotlib(0, 0, 1)
ax.quiver(0, 0, 0, dx, dy, dz, color="blue", length=arrow_len, normalize=True)
ax.text(*to_matplotlib(arrow_len*1.1, 0, 0), "+x")
ax.text(*to_matplotlib(0, arrow_len*1.1, 0), "+y")
ax.text(*to_matplotlib(0, 0, arrow_len*1.1), "+z")
# Change perspective here (world cam)
ax.view_init(elev=15, azim=-25)
#ax.view_init(elev=0, azim=-90)
def rays(points, z_target):
colors = [
'#FF0000',
'#0000FF',
'#00FF00',
'#FF8000',
'#8000FF',
'#00FFFF',
'#FF00FF',
'#FFFF00'
]
i=0
for p in points:
# p is in USER-Coordinates
x, y, z = to_matplotlib(
[p[0], p[0]],
[p[1], p[1]],
[p[2], z_target], # orthogonal projection on z = z_target
)
ax.plot(x, y, z, color=colors[i], alpha=0.5)
i+=1
def update(theta):
ax.cla()
init()
# Back face center and parameters in USER coordinates
cx, cy, zb = 4.0, 3.5, 1.0
s = 1.0 # side length
h = s / 2.0
zf = zb + s # front face z
pivot = np.array([cx, cy, (zb + zf)/2.0])
axis= np.array([0, 1, 0])
# Back face corners (on z = zb)
bl_b = rotate(theta, axis, np.array([cx - h, cy - h, zb]), pivot) # bottom-left
br_b = rotate(theta, axis, np.array([cx + h, cy - h, zb]), pivot) # bottom-right
tr_b = rotate(theta, axis, np.array([cx + h, cy + h, zb]), pivot) # top-right
tl_b = rotate(theta, axis, np.array([cx - h, cy + h, zb]), pivot) # top-left
# Front face corners (on z = zf)
bl_f = rotate(theta, axis, np.array([cx - h, cy - h, zf]), pivot)
br_f = rotate(theta, axis, np.array([cx + h, cy - h, zf]), pivot)
tr_f = rotate(theta, axis, np.array([cx + h, cy + h, zf]), pivot)
tl_f = rotate(theta, axis, np.array([cx - h, cy + h, zf]), pivot)
z_target = -4
rays([bl_b, br_b, tr_b, tl_b, bl_f, br_f, tr_f, tl_f], z_target);
faces_user = [
[bl_b, br_b, br_f, bl_f], # bottom side (y = cy - h)
[br_b, tr_b, tr_f, br_f], # right side (x = cx + h)
[tr_b, tl_b, tl_f, tr_f], # top side (y = cy + h)
[tl_b, bl_b, bl_f, tl_f], # left side (x = cx - h)
]
faces_mat = [[to_matplotlib(*p) for p in face] for face in faces_user]
# from faces_user ...
proj_faces_user = [[[p[0], p[1], z_target] for p in face] for face in faces_user]
# ... to projected coordinates (with y/z swap)
proj_faces = [[to_matplotlib(*p) for p in face] for face in proj_faces_user]
for face in faces_mat:
xs = [p[0] for p in face] + [face[0][0]]
ys = [p[1] for p in face] + [face[0][1]]
zs = [p[2] for p in face] + [face[0][2]]
ax.plot(xs, ys, zs, linewidth=1.25, color="purple")
for face in proj_faces:
xs = [p[0] for p in face] + [face[0][0]]
ys = [p[1] for p in face] + [face[0][1]]
zs = [p[2] for p in face] + [face[0][2]]
ax.plot(xs, ys, zs, linewidth=1.25, color="purple")
theta += 5
end = 180
steps = 2
theta = 0
ani = FuncAnimation(fig, update, frames=list(range(0, end, steps)), interval=30, init_func=init)
#foo=ani.save(path/filename.gif, writer="pillow", fps=30)
init()
plt.tight_layout()
plt.show()
Affine Transformation
The statement that two parallel vectors remain parallel after an orthographic projection is applied is a fundamental property of an affine transformation [📖VB15, 118].
An affine transformation is a transformation of the form
where is a linear transformation. Hence, an affine transformaton is simply a linear transformation to which a translation is applied.
Intuitively, we can see that this statement holds. Given two parallel vectors:
Their cross product is the zero vector
which yields three initial conditions:
Obviously, removing the z component from and preserves the parallelism for the -plane, as the third component of the cross product is still zero:
Our intution tells us that since these new vectors are parallel, translating both by an equal amount in the same direction will not change their parallelism. Therefor, adding the same z-component to both vectors yields to parallel vectors
This intuition can be formalized using the definition of an affine transformation. We can write our orthographic projection Matrix as an affine transformation consisting of the sum of a linear combination
and a translation vector . That affine transformations preserve parallelism will be shown for the general case in the next section.
Proof that Affine Transformations preserve Parallelism
Let be an affine transformation
Let's define two lines , with direction vectors and , where are points on the respective lines.
Since the lines are parallel, we can write as the scaled version of
Applying the affine transformation to the points and yields a new vector with direction :
Since is a linear transformation, we can simplify this to
This shows that the new direction vector is the result of applying the linear part of the transformation to the original direction vector. Applying the same computation to gives us
Since we know , we can therefore conclude:
Hence, is scaled by , which shows that they are parallel. This proves that any affine transformation preserves parallelism.
Deriving the Orthographic Projection Matrix
In the following, we will derive the orthographic projection matrix required to map an arbitrary cubic volume from view space coordinates9 to the canonical view volume .
We begin with defining the coordinates of the Volume to be projected (see Figure 2):
The naming convention applies after the transformations to camera space. In this space, the camera is located at the origin , looking down the negative -axis. is defined by coordinates relative to the z-axis. Figure 2 shows therefore a representation of camera space.
Note that , represent positive distances to the near and far clipping planes. By definition, the near plane is closer to the origin, so .
However, in camera space where the view direction is along the negative -axis, these values correspond to negative coordinates. The near plane is located at
The far plane is located at
Therefore, the following holds:
When deriving the coordinates for the canonical view volume, we adopt standard OpenGL convention in form of a left handed coordinate system, that is, the view direction is along the positive instead of the negative -axis. For our case this means that we have to mirror the -axis at the origin, which will be considered by using a negative -component in the following orthographic projection matrix (see [📖RTR, 95]).
We will first examine the requirements for the affine transformation. Since all vertices of V must fit into the unit cube , which - probably unlike - is located at the origin, a translation and a scaling are necessary. Thus, we can directly define a transformation matrix of the form
where is the scaling matrix and is the translation vector.
We thus obtain the affine transformation that, when multiplied by an arbitrary vertex , transforms it into the canonical view volume:
Here, we have negated the -component, as we must mirror the -axis (see above).
From this, we can derive a system of linear equations for which the following conditions must be met:
We explicitly use and here because after the view transformation, the near and far values are given to us as positive distances. For the correct derivation, they must therefore be re-inserted as negative values.
Solving for and , respectively, yields:
Substituting with gives us
Solving analogously for and , we obtain
We can now solve for . We obtain
Which results in the orthographic projection matrix
The near plane is called the "image plane" by the Red Book: It's the plane closest to the eye and perpendicular to the line of sight (see [📖KSS17, 902]). Lehn et al. equally describe the projection plane identical to the near clipping plane [📖LGK23, 166].
As such, with orthographic projection, rays from vertices of the view volume in camera space intersect the projection plane - that is usually between the near and far plane - perpendicularly. Then, after the orthographic projection is applied, clip space coordinates are transformed into the Canonical View Volume and NDCs, where the perpendicular relationship is preserved due to the parallelism-preserving properties of affine transformations. Consequently, the projection rays remain perpendicular to any -plane at in NDC space. Think of the projection plane at in the final image on screen, where the -component of the NDC coordinates is only used for depth testing.
Proof that (l, b, -n, 1) maps (-1, -1, -1, 1)
Let be the homogeneous coordinate with (view space coordinates). We can then solve with for
We can analogously show that maps .
Perspective Projection
In orthographic projection, the viewer is theoretically at an infinite distance from the projection surface, so that the rays from the impact points of the projected geometry, which are perpendicular to the projection surface, only converge at an infinite distance. For this reason, the effect of depth is absent, because objects farther back in the view volume are mapped exactly onto the projection surface and therefore correspond to their actual dimensions in space10.
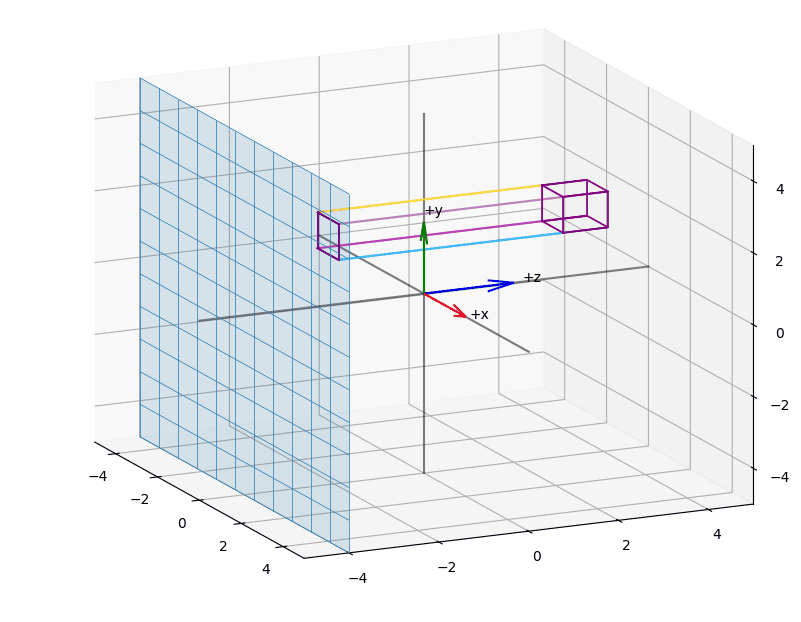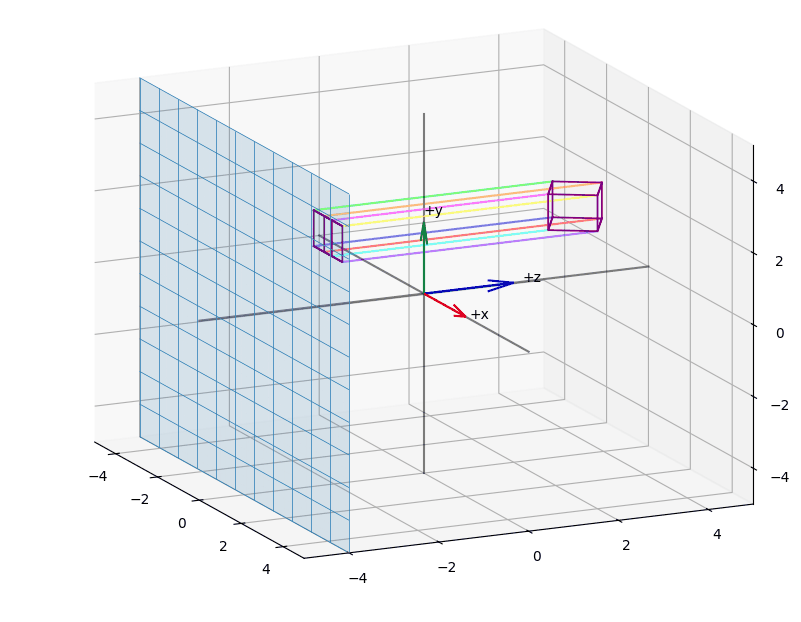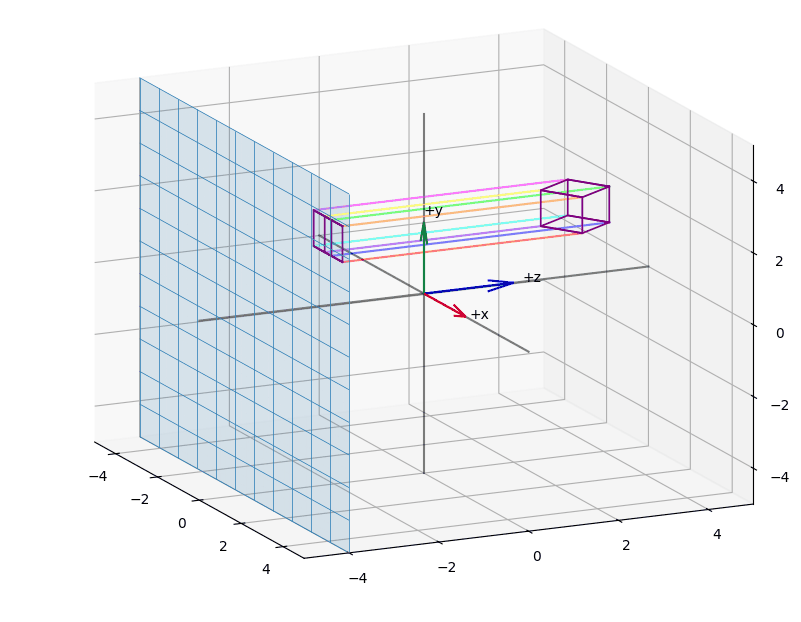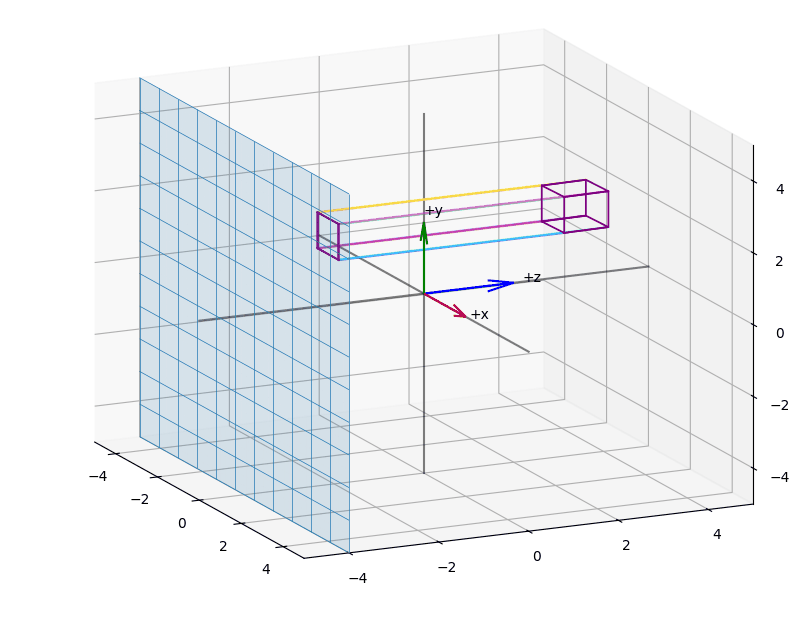
Perspective projection, on the other hand, uses the camera position as a center of projection where all projection rays converge, forming a pyramid. The near and far planes clip this pyramid, defining a truncated pyramid known as the view frustum. Due to this pyramid shape, the near plane is necessarily smaller than the far plane - a key difference from orthographic projection, where the view volume is in a rectangular shape (see Figure 7).
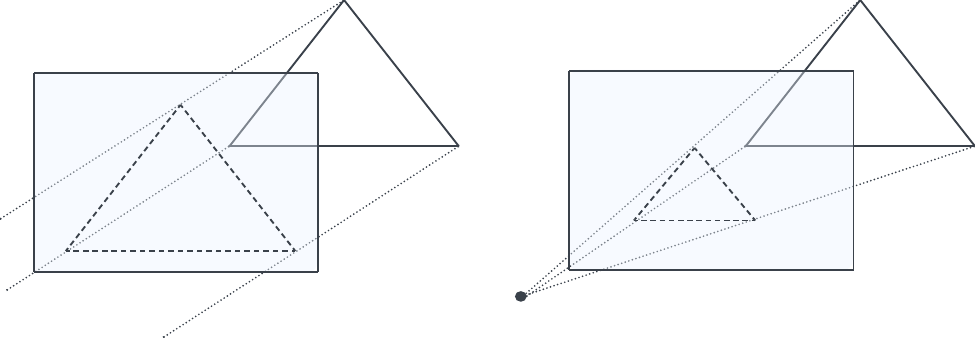
Even with a View Frustum, the near and far planes are understood as clipping planes. However, the dimension of the far plane is also determined by another parameter, Field-of-View (fov), as we will see in the following: This parameter describes the viewer's field of vision, i.e., the area that the viewer can capture.
If the fov is correspondingly large, this affects the dimension of the far plane, and thus the volume of the View Frustum becomes larger, and thus also the amount of objects that can be captured and projected onto the near plane. This affects the size of the projections - intuitively, more objects must be projected onto the limited surface of the near plane. As a result, individual objects must appear smaller to fit within the view.
The distance of the camera from the object also has a direct effect on its projected size.
However, the distance of the near plane from the projection center has no effect on the size of displayed objects, as long as the fov remains constant. We will come back to this in a later section.
We will also see that with perspective projection, after the conversion to NDC, the property that parallel lines are preserved no longer holds for the general case due to the perspective division.
Deriving the Perspective Projection Matrix
Figure 8 shows the geometric relationships between the parameters described in the introductory text. Besides the already mentioned fov , the aspect ratio is also shown, which describes the ratio between the width () and height () of the projection surface. In the following, we will first assume an aspect ratio of 1:1 and thus an equal in both the vertical and horizontal directions, before we use the field of view only for the vertical direction, while the horizontal is determined by the vertical field-of-view (fovy) and the aspect ratio, as is common in OpenGL.
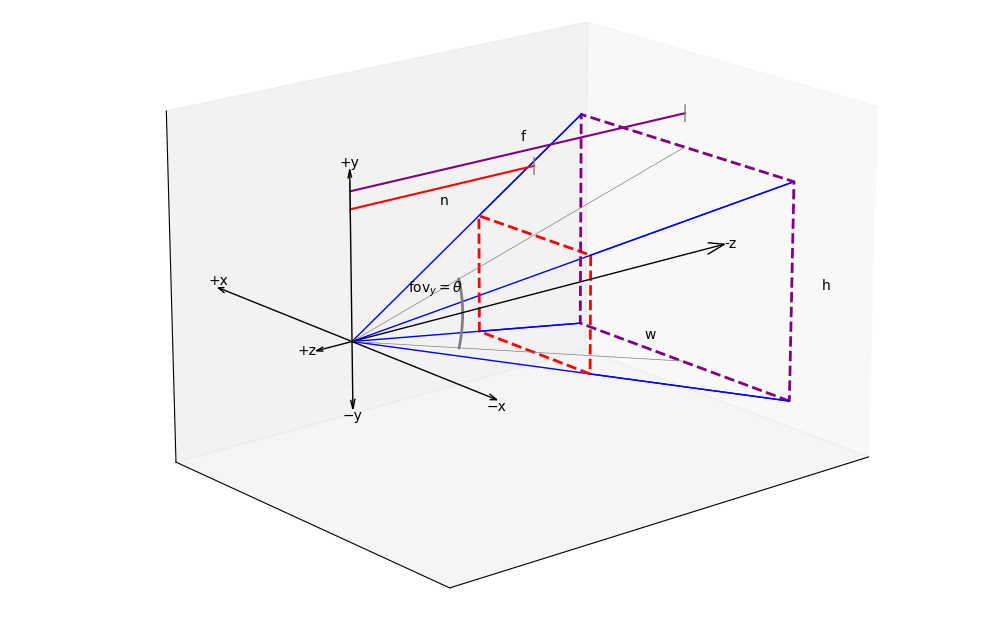
A simple perspective projection
As with orthographic projection, we can first consider the simple case of projecting onto the -plane at .
The projection of the point onto the plane to can be computed as follows:
According to the similar triangles theorem, the following holds:
From this we obtain
Analogously for :
From this, a transformation matrix can be derived that maps the point to the point :
After the perspective division by the -component of the resulting homogeneous vector, we obtain:
and thus the homogeneous vector that represents :
As Lehn et al. note, the final row of the matrix deviates from the form seen in affine transformation matrices so far. Consequently, a vertex transformed by this matrix results in a clip-space coordinate that is not yet normalized, which is achieved by the perspective division [📖LGK23, 176]. (After this division, the fourth component is discarded, yielding the final coordinates in NDC.)
The matrix notation follows Lehn et al. [📖LGK23, 171]. An alternative form is presented by Akenine-Möller et al. [📖RTR, 96]:
The term in the fourth row is set to , with being the absolute distance to the projection plane on the negative -axis. This accounts for the convention of looking down the negative -axis in view space and the axis-flip when converting to clip space, as was established during the derivation of the orthographic projection matrix. It is easy to show that both matrices yield the same results when both consider the axis flip.
Perspective Projection Matrix
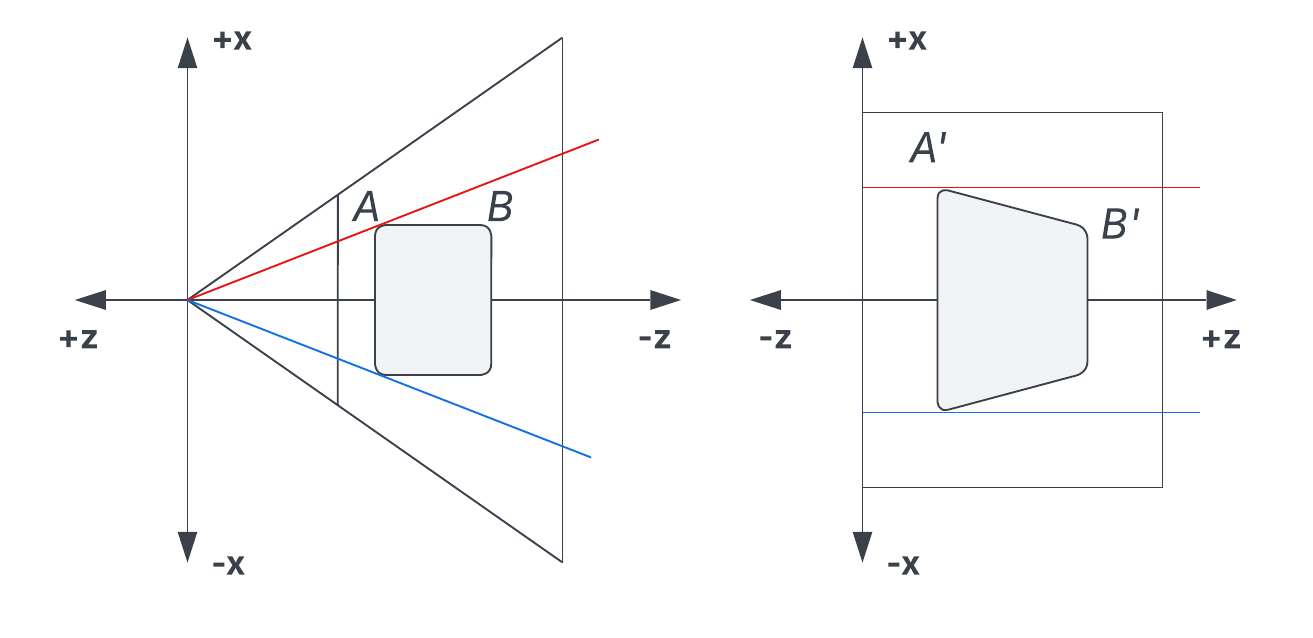
Functions like glm::perspective11 create a projection matrix that transform view space coordinates into clip space. The subsequent perspective divide, a step automatically handled by OpenGL, converts these coordinates into NDC. This process creates the illusion of perspective, as dividing by the -component scales each vertex's position relative to its distance from the camera.
Unlike an orthographic projection, the component od the resulting clip-space coordinate is not . Instead, it is proportional to the absolute depth of the vertex in view space (). During the perspective divide, a larger for a vertex farther away from the camera result in smaller NDC coordinates, causing the object to appear smaller on screen. Conversely, smaller contribute to larger NDC coordinates. The effect is illustrated in Figure 9.
{kind=link}
The vanishing point, characteristic for depth-rendered illustrations, is the finite point on the screen where parallel lines appear to converge. In 3D graphics, this effect is a direct result of the perspective divide.
As derived previously, a simple perspective projection maps a point to the following coordinates on the projection plane after the perspective divide:
To find the vanishing point for lines parallel to the -axis, we can examine the limit of this point as it moves to infinity:
This shows that regardless of their initial and values, all lines parallel to the -axis converge to the single point
on the projection plane. This point of convergence is the vanishing point12 (see [📖LGK23, 172]).
To construct a perspective projection matrix, the following parameters define the view frustum:
- Vertical Field of View : The vertical field of view, denoted as .
- Aspect ratio : The ratio of the viewport's width and its height , .
- Near plane distane : The distance from the camera's origin to the near clipping plane.
- Far plane distance : The distance from the camera's origin to the far clipping plane.
The resulting matrix transforms coordinates from camera space into clip space coordinates. Following the matrix multiplication, the subsequent perspective division maps these coordinates into NDCs.
Square Aspect Ratio
The following derivation holds for a symmetric view frustum with an aspect ration of , which means that .
For this view frustum, there are 4 extreme frustum points on a plane :
We begin with the derivation of the -component in the first column of the transformation matrix using a point that contains as its -component and as its -component.
The diaginal entries scale in clip space. must be scaled such that after the perspective division, it is mapped to in the unit cube, which represents the boundary of the maximum display range.
The maximum visible range is determined by the field of view. In this case, since we are dealing with a half-space in the coordinate system of camera space, this angle to the right in camera space is
Using the definition of the tangent, which relates the positive lengths of the triangle sides, we can therefore state
Due to the given symmetry, we can note for the triangle:
For deriving , we consider absolute values. Since , we write:
must be mapped to after the perspective division, so the following must hold:
We rearrange to get:
The derivation is valid for negative as well as positive - it can be easily shown that in that case, only the sign of the result is inverted:
Let
For , the following must hold:
which gives us
Since a symmetric view frustum is assumed, the derivation for and and is identical.
Bot scaling factors are identical in a symmetric frustum. We can therefore define a single factor
This simplifies to
Deriving Scaling and Transformation for the -component
To derive and understand the necessity of , we must consider the perspective division. Without , mapping to and to would lead to a contradiction
Therefore, considering as a bias is essential - it prevents the -component from simply cancelling out and enables the non-linear mapping of the -coordinate.
In analogy to the derivation of the components for the orthographic projection matrix, the following conditions must be met to map to , taking the perspective division into account. We first determine the resulting vector in Clip Space:
With perspective division, the following must hold:
The conditions for the mapping of to in NDC are analogously:
Equating and solving yields
Thus we obtain the transformation matrix for a symmetric view frustum:
Arbitrary Aspect Ratio
We now consider the previously introduced aspect ratio , which describes the ratio between the viewport's width and height. The height is easily derived with the help of the vertical field of view and the distance to the far plane:
Hence, . Given and , we can easily derive the width of the viewport now:
Corresponding to the derivation of in the case of a symmetric frustum with an aspect ratio of 1.0, we derive :
The following known condition must hold:
We rearrange to get13:
It is easy to see that the condition
is satisfied for :
Since the aspect ratio affects scaling on the -axis, we derive the final form for the perspective projection matrix as used with OpenGL:
In a previous section, we have stated that the distance of the near plane from the projection center has no effect on the size of displayed objects, as long as the fov remains constant.
With the full derivation of the projection matrix, it is easy to see why this is the case: The fov and aspect ratio exclusively determine the scaling of the - (width) and - (height) components. In this regard, they function analogously to a focal length [📖LGK23, 194], defining the zoom and shape of the view.
Conversely, the and values affect the terms that calculate the final -coordinate in clip-space: Their purpose is to define the depth boundaries of the view frustum that get mapped into the unit cube, i.e., those parameters control depth clipping and precision, but not the projected size of an object.
z-Buffer and z-Fighting
Although vertices undergo a series of transformation - from clip space in homogeneous coordinates through perspective division, to normalized device coordinates and finally 2D screen coordinates - the z-component remains an important value for any graphics library. After the perspective transform, the -component becomes and is quantized [📖RTR, 1014]. During depth testing, this -component is used to determine whether a fragment lies before or behind a surface represented by the current -buffer value: If it lies before, it's z-value is used to update the z-buffer, and the computing goes on until all objects were processed [📖LGK23, 298]14.
Due to the non-linear nature of the perspective projection, depth precision is not uniform - it is highest near the camera and decreases further away, which is easy to show. Given the final form of the perspective projection matrix, the -component before perspective division is
After the perspective divide, we obtain
which gives us one constant term and a term depending from . The derivative of this term is
which shows that this represents a monotonically decreasing function (decreasing towards , increasing towards ). Furthermore, the rate of change diminishes with distance.
For objects close to the far plane, it is possible that different surfaces are mapped to nearly identical -values with limited floating-point precision, resulting in flickering intersections (-fighting) [📖KSS17, 227 f.]. Akenine-Möller et al. introduce ways to increase depth precision in [📖RTR, 100 f.].
Updates:
- 17.09.2025 Initial publication.
Footnotes
-
A common stumbling block when you’re used to absolute screen pixels: How are you supposed to scale anything when there’s "nothing" to scale against? ↩
-
See Change of Coordinates and Applications to View Matrices ↩
-
see https://en.wikipedia.org/wiki/Camera_obscura, retrieved 20.08.2025 ↩
-
see https://registry.khronos.org/OpenGL-Refpages/gl4/html/gl_Position.xhtml, retrieved 05.09.2025 ↩
-
"Units normalized such that divide by w leaves visible points between -1.0 to +1.0" (idb.). Additionally, de Vries provides a good introduction into the coordinate systems used by OpenGL in [📖Vri20] ↩
-
Additionally, user-defined clipping is configurable, which allows for custom clipping planes to be added to the scene [📖KSS17, 228 f.]. ↩
-
Mathematically, the NDC cube is a continuous space containing an uncountable set of real numbers. These values are represented by a finite set of discrete floating-point numbers (typically IEEE 754 32-bit floats) that approximate the ideal real values. ↩
-
In [📖SWH15, 40 f.], Sellers et al. note that the practically visible range is described by in , and that this also applies to the NDC -axis. However, other literature explicitly refers to a range of in all directions (e.g., [📖RTR, 94], [📖LGK23, 174]). It can therefore be assumed that the authors may refer to a range controlled by
glClipControl[📖KSS17, 230], which allows for changing the NDC depth convention from to . ↩ -
The projection occurs after the view/camera space transformation. ↩
-
We do not consider the mapping to the canonical view volume in OpenGL here, but instead an orthographic projection onto the xy-plane at z=-n. ↩
-
https://glm.g-truc.net/0.9.9/api/a00243.html#ga747c8cf99458663dd7ad1bb3a2f07787, retrieved 15.09.2025 ↩
-
This is comparable to an orthographic projection, where the center of projection lies at infinity. As a result, the projection rays are parallel to each other (in this case, parallel to the -axis) - see Figure 7. ↩
-
By the similar-triangles argument, the near plane satisfies the same relation. ↩
-
See [📖SWH15, 376 ff.] for an introdcution to
glDepthFunc(), which lets you control the comparision function used with depth testing in OpenGL. ↩
References
- [KSS17]: Kessenich, John and Sellers, Graham and Shreiner, Dave: The OpenGL Programming Guide (2017), Addison Wesley [BibTeX]
- [SWH15]: Sellers, Graham and Wright, Richard S. and Haemel, Nicholas: OpenGL Superbible: Comprehensive Tutorial and Reference (2015), Addison-Wesley Professional [BibTeX]
- [Vri20]: de Vries, Joey: Learn OpenGL (2020), Kendall & Wells [BibTeX]
- [RTR]: Akenine-Möller, Tomas and Haines, Eric and Hoffman, Naty: Real-Time Rendering (2018), A. K. Peters, Ltd. [BibTeX]
- [LGK23]: Lehn, Karsten and Gotzes, Merijam and Klawonn, Frank: Introduction to Computer Graphics: Using OpenGL and Java (2023), Springer, 10.1007/978-3-031-28135-8 [BibTeX]
- [VB15]: Van Verth, James M. and Bishop, Lars M.: Essential Mathematics for Games and Interactive Applications (2015), A. K. Peters, Ltd. [BibTeX]